Detecting NSFW Images in PDFs Using Python and the NSFW API
Introduction
In today’s digital age, the prevalence of NSFW (Not Safe For Work) content in digital documents is a growing concern. According to recent studies, approximately 20% of all documents shared in professional environments contain some form of inappropriate content, including NSFW images. This statistic underscores the urgent need for effective solutions to identify and filter out such content to maintain a safe and productive workspace.
Detecting NSFW images in PDFs is crucial for several reasons. For businesses, it helps prevent legal issues, maintains workplace professionalism, and protects the company’s reputation. Educational institutions need to ensure that the materials provided to students are appropriate and free from harmful content. Digital content platforms, which host a vast amount of user-generated content, must vigilantly monitor for NSFW images to uphold community standards and provide a safe environment for all users. Failure to detect and manage NSFW content can lead to significant consequences, including legal liabilities, damaged reputations, and a loss of user trust.
In this blog post, we will explore how to leverage AI technology to detect NSFW images in PDFs efficiently. Specifically, we will focus on utilizing the NSFW API from API4AI, a powerful tool that simplifies the process of identifying inappropriate content. We will provide a detailed step-by-step guide on developing a Python script that integrates with the NSFW API to extract images from PDFs and analyze them for NSFW content. By the end of this post, you will have a comprehensive understanding of how to implement this solution in your own workflows, ensuring that your digital documents are safe and compliant.
Understanding NSFW Content
Definition of NSFW: What Constitutes NSFW Content?
NSFW (Not Safe For Work) content refers to any material that is inappropriate for viewing in a professional or public setting. This includes explicit content, such as pornography, graphic violence, and other obscene images that can be offensive or disturbing. The term NSFW is broadly used to categorize content that should be restricted to private viewing to avoid discomfort, offense, or disruption in professional environments.
Examples of NSFW Content
NSFW content can manifest in various forms within digital documents. Common types of NSFW images found in PDFs include:
Pornographic Images: Visual depictions of explicit sexual acts or nudity.
Graphic Violence: Images portraying extreme violence, blood, and gore.
Obscene Material: Depictions of lewd acts, gestures, or other forms of explicit content.
Hate Symbols: Images containing hate speech, symbols, or gestures that promote discrimination or hostility.
These types of content are not only inappropriate but can also create a hostile environment, making it essential to detect and remove them from professional and educational materials.
Risks and Consequences
Failing to detect NSFW content in PDFs can lead to several significant risks and consequences:
Legal Issues: Businesses and institutions can face legal repercussions if they distribute or allow the presence of NSFW content in their materials. This includes potential lawsuits for distributing obscene material or creating a hostile work environment.
Workplace Harassment: NSFW content can contribute to workplace harassment, making employees feel uncomfortable or unsafe. This can result in complaints, high turnover rates, and decreased productivity.
Reputation Damage: The presence of NSFW content in publicly accessible documents can severely damage the reputation of an organization. Clients, partners, and the public may lose trust in an organization that fails to manage inappropriate content.
Compliance Violations: Many industries have strict regulations regarding the distribution of content. Organizations must comply with these regulations to avoid penalties and maintain good standing within their industry.
By understanding what constitutes NSFW content and recognizing the potential risks and consequences, organizations can take proactive steps to ensure their digital documents are safe and appropriate for all audiences. In the following sections, we will delve into how to leverage AI technology, specifically the NSFW API, to effectively detect and manage such content in PDFs.
The Challenge of Detecting NSFW Content in PDFs
Technical Difficulties
Detecting NSFW images in PDFs poses several technical challenges that make the task far from straightforward:
Varying Image Formats: PDFs can contain images in multiple formats such as JPEG, PNG, GIF, and even vector graphics. This diversity requires a detection system to be versatile enough to handle different file types and compression methods.
Embedded Images: Images within PDFs can be embedded in various ways. They might be directly embedded as part of the document's content stream, or they might be referenced from external sources. This makes extracting all images from a PDF a non-trivial task.
Encryption: Many PDFs are encrypted or password-protected to ensure the confidentiality and security of their content. This encryption needs to be dealt with appropriately to access the images within the document.
Complex Layouts: PDFs can have complex layouts with overlapping text and images, making it difficult to accurately extract and identify images without also capturing unwanted elements.
Scalability: Processing large volumes of PDFs quickly and efficiently requires significant computational resources, which can be a limiting factor for many organizations.
Manual vs. Automated Detection
Comparing manual detection methods with automated AI-based solutions highlights the advantages of leveraging technology:
Manual Detection: Involves individuals reviewing each page of a PDF to identify NSFW content. This approach is time-consuming, labor-intensive, and prone to human error. It’s impractical for handling large volumes of documents and may lead to inconsistent results.
Automated AI-based Detection: Utilizes machine learning algorithms to analyze images within PDFs. Automated systems, like those using the NSFW API, can quickly and accurately process large numbers of documents. These systems can be trained to recognize various types of NSFW content with high precision, reducing the workload on human reviewers and increasing overall efficiency.
Importance of Accuracy
Accuracy is paramount when detecting NSFW content to avoid the pitfalls of false positives and negatives:
False Positives: Incorrectly identifying safe content as NSFW can lead to unnecessary censorship, loss of legitimate information, and potential frustration for users who have to manually review and correct these errors.
False Negatives: Failing to detect actual NSFW content poses significant risks, including the distribution of inappropriate material, potential legal repercussions, and damage to an organization's reputation.
Balancing Sensitivity and Specificity: Achieving high accuracy involves balancing sensitivity (detecting all NSFW content) and specificity (correctly identifying non-NSFW content). Automated systems can be fine-tuned to optimize this balance, ensuring robust and reliable detection.
Continuous Improvement: AI models can continuously learn and improve from new data, enhancing their detection capabilities over time. This adaptability is crucial for maintaining high accuracy as new types of NSFW content emerge.
By understanding and addressing these challenges, organizations can implement effective strategies for detecting NSFW images in PDFs, leveraging the power of automated AI solutions like the NSFW API to ensure their digital content is appropriate and compliant.
AI-Powered Solutions for Detecting NSFW Images
Overview of AI and Machine Learning
Artificial Intelligence (AI) and Machine Learning (ML) have revolutionized the way we approach image detection. AI involves the creation of algorithms that can perform tasks that typically require human intelligence. Machine Learning, a subset of AI, enables these algorithms to learn from data and improve their performance over time. In the context of image detection, AI and ML use techniques like convolutional neural networks (CNNs) to analyze visual data and identify patterns.
These technologies can be trained on vast datasets of images to recognize different types of content, including NSFW material. By processing and learning from labeled examples, AI models can develop the ability to accurately classify new, unseen images based on the features they have learned.
Introduction to NSFW API
The NSFW API, provided by API4AI, is a specialized tool designed to simplify the detection of NSFW images. This API leverages advanced AI models trained specifically to identify inappropriate content in images. By integrating this API into your applications, you can automate the process of scanning and classifying images within PDFs, ensuring that any NSFW content is detected and flagged appropriately.
The NSFW API streamlines the implementation process, removing the need for organizations to develop and train their own AI models. It offers a ready-to-use solution that can be easily integrated into various applications and workflows, allowing businesses to focus on their core activities while maintaining a safe and compliant digital environment.
Features of NSFW API
The NSFW API offers several key features and benefits that make it an effective tool for NSFW detection:
High Accuracy: The API is powered by state-of-the-art AI models that have been extensively trained on diverse datasets. This ensures high accuracy in detecting various types of NSFW content, minimizing false positives and negatives.
Ease of Integration: The API is designed for easy integration with existing systems. It provides clear documentation and straightforward endpoints, enabling developers to quickly implement NSFW detection into their applications using standard HTTP requests.
Scalability: The NSFW API can handle large volumes of images, making it suitable for businesses and platforms of all sizes. Whether you're processing a few documents or thousands, the API scales to meet your needs without compromising performance.
Real-Time Processing: The API offers real-time processing capabilities, allowing for immediate detection and response. This is crucial for applications that require quick identification of NSFW content, such as content moderation platforms.
Versatility: The NSFW API can be used in a variety of applications, from scanning images within PDFs to monitoring user-uploaded content on social media platforms. Its versatility makes it a valuable tool for any organization dealing with digital images.
Continuous Updates: The API4AI team continuously updates and improves the models behind the NSFW API, ensuring that it stays effective against new types of NSFW content and adapts to evolving standards and requirements.
By leveraging the NSFW API, organizations can harness the power of AI to efficiently and accurately detect NSFW images in their digital documents. This not only helps maintain a professional and safe environment but also reduces the burden on human reviewers, allowing them to focus on more complex tasks that require human judgment.
Developing a Python Script for NSFW Detection
In this section, we will walk you through the process of developing a Python script to detect NSFW images in PDFs using the NSFW API. We'll cover setting up the environment, extracting images from PDFs, integrating the NSFW API, and testing the complete script.
Setting Up the NSFW API
To use the NSFW API, you first need to set up an account with Rapid API Hub (where API4AI’s solutions are hosted) and obtain an API key. This key will be used to authenticate your requests to the NSFW API.
Create an Account on Rapid API Hub website.
Find the NSFW API: Once logged in, follow this link to find NSFW API.
Subscribe to the API on the page with subscription plans.
Obtain Your API Key:
After subscribing, navigate to the Dashboard.
On the left pat of the screen you should see something like “default-application_xxxxxx“.
Go to Authorization and copy Application Key
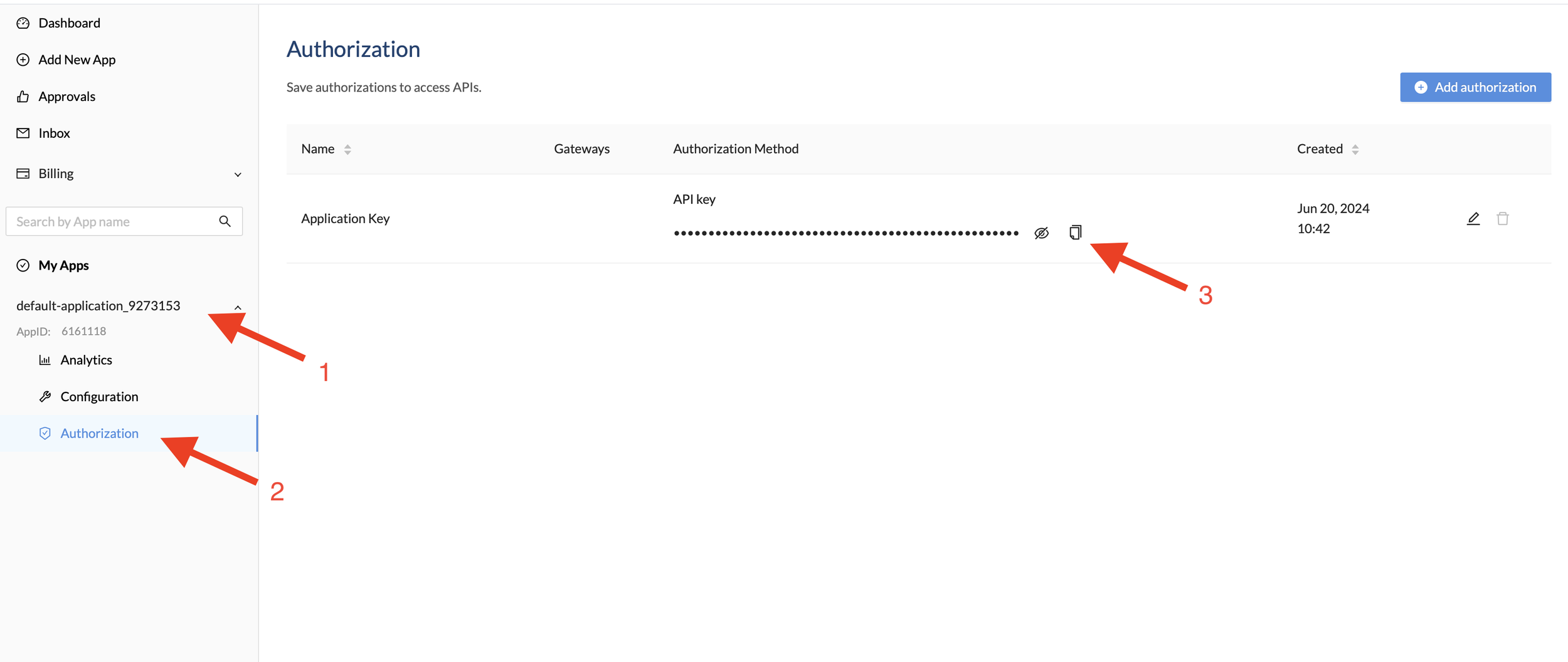
Rapid API Hub: Obtaining API Key
Prerequisites
Before diving into the code, ensure you have the following prerequisites:
Python: Make sure Python is installed on your system. You can download it from the official Python website.
Required Libraries: Install the necessary Python libraries (
requests) by using a package manager like pip. This will set up your development environment and prepare you for scripting.
Parse Command-line Arguments
To make the script flexible, we will use the argparse library to handle command-line arguments. This allows users to specify the PDF file path and the API key directly from the command line, enhancing the script’s usability.
First, create a function to parse these arguments. This function will set up an argument parser, describe the arguments, and return the parsed arguments. By setting up command-line arguments, the script becomes adaptable to various input files and configurations without requiring changes to the code itself.
def parse_args():
"""Parse command line arguments."""
parser = argparse.ArgumentParser()
parser.add_argument('--api-key', help='Rapid API key.', required=True) # Get your token at https://rapidapi.com/api4ai-api4ai-default/api/nsfw3/pricing
parser.add_argument('pdf', type=Path,
help='Path to a pdf.')
return parser.parse_args()Getting NSFW Probabilities for Each PDF Page
With the command-line arguments in place, the next step is to write a function capable of processing each page of the PDF to extract images and send them to the NSFW API for analysis.
Actually, this step is going to be fairly simple because the NSFW API supports PDFs out-of-the-box. Therefore, we can directly send the PDF for processing and parse the result, which will contain the NSFW probability for each PDF page.
def get_nsfw_probs(pdf_path: Path, api_key: str) -> list:
"""
Get probabilities of NSFW content in PDF using NSFW API.
Returns list of probabilities that content is NSFW, representing pdf pages.
"""
# We strongly recommend you use exponential backoff.
error_statuses = (408, 409, 429, 500, 502, 503, 504)
s = requests.Session()
retries = Retry(backoff_factor=1.5, status_forcelist=error_statuses)
s.mount('https://', HTTPAdapter(max_retries=retries))
url = f'{API_URL}'
with pdf_path.open('rb') as f:
api_res = s.post(url, files={'image': f},
headers={'X-RapidAPI-Key': api_key}, timeout=20)
api_res_json = api_res.json()
# Handle processing failure.
if (api_res.status_code != 200 or
api_res_json['results'][0]['status']['code'] == 'failure'):
print('Image processing failed.')
sys.exit(1)
# Each page is a different result.
probs = [result['entities'][0]['classes']for result in api_res_json['results']]
return probsMain function
The next step is to analyze the results to make an informed decision. Essentially, the NSFW API returns a probability for each page, indicating the likelihood that it contains NSFW content. Depending on business requirements and the desired “strictness” of your solution, you can adjust the threshold for considering a page as NSFW. This means you can set the threshold higher or lower based on how stringent you want the filtering to be. In our test script, we will use a threshold value of 0.5.
By carefully analyzing these probabilities, we can tailor the system to meet specific needs, ensuring that the content filtering aligns with the organization's standards and expectations. This flexibility allows for a customizable approach, making the solution adaptable to various scenarios and requirements. Additionally, by using the threshold of 0.5 in our test script, we can establish a baseline for further fine-tuning and optimization, leading to a more precise and effective content analysis process.
def main():
"""
Script entry function.
"""
args = parse_args()
probs = get_nsfw_probs(args.pdf, args.api_key)
if any([prob['nsfw'] > 0.5 for prob in probs]):
print('PDF contains NSFW content.')
else:
print('PDF is safe for work.')
if __name__ == '__main__':
main()Complete Python Script
Combining all parts, you will have a complete Python script that integrates all the steps necessary to detect NSFW images in PDFs. Essentially, it is the simplest and most concise code for implementing the analysis of PDFs. The script can be easily customized to suit specific needs, allowing for integration into various business pipelines.
This flexibility is crucial as it enables you to adapt the code to different scenarios and requirements, ensuring it meets the unique demands of your organization. Whether you need to adjust the thresholds, modify the processing steps, or incorporate additional features, the script provides a solid foundation that can be tailored to your specific use case. By leveraging this adaptable approach, you can streamline the process of detecting NSFW content in PDFs, making it more efficient and effective for your business needs.
"""
Check NSFW content in PDF using NSFW API.
Run script:
`python3 main.py --api-key <RAPID_API_KEY> <PATH_TO_PDF>
"""
import argparse
import sys
from pathlib import Path
import requests
from requests.adapters import Retry, HTTPAdapter
API_URL = 'https://nsfw3.p.rapidapi.com/v1/results'
def parse_args():
"""Parse command line arguments."""
parser = argparse.ArgumentParser()
parser.add_argument('--api-key', help='Rapid API key.', required=True) # Get your token at https://rapidapi.com/api4ai-api4ai-default/api/nsfw3/pricing
parser.add_argument('pdf', type=Path,
help='Path to a pdf.')
return parser.parse_args()
def get_nsfw_probs(pdf_path: Path, api_key: str) -> list:
"""
Get probabilities of NSFW content in PDF using NSFW API.
Returns list of probabilities that content is NSFW, representing pdf pages.
"""
# We strongly recommend you use exponential backoff.
error_statuses = (408, 409, 429, 500, 502, 503, 504)
s = requests.Session()
retries = Retry(backoff_factor=1.5, status_forcelist=error_statuses)
s.mount('https://', HTTPAdapter(max_retries=retries))
url = f'{API_URL}'
with pdf_path.open('rb') as f:
api_res = s.post(url, files={'image': f},
headers={'X-RapidAPI-Key': api_key}, timeout=20)
api_res_json = api_res.json()
# Handle processing failure.
if (api_res.status_code != 200 or
api_res_json['results'][0]['status']['code'] == 'failure'):
print('Image processing failed.')
sys.exit(1)
# Each page is a different result.
probs = [result['entities'][0]['classes']for result in api_res_json['results']]
return probs
def main():
"""
Script entry function.
"""
args = parse_args()
probs = get_nsfw_probs(args.pdf, args.api_key)
if any([prob['nsfw'] > 0.5 for prob in probs]):
print('PDF contains NSFW content.')
else:
print('PDF is safe for work.')
if __name__ == '__main__':
main()Testing the Script
To test the script, follow these steps:
Prepare a PDF: Have a sample PDF file with embedded images ready for testing. This ensures that you can verify the script's functionality in a realistic scenario. Here you can download a pdf sample to start.
Run the Script: Execute the script in your terminal, providing the path to the PDF file and your API key as arguments.
python3 main.py --api-key YOUR_API_KEY ./nsfw.pdf
PDF contains NSFW content.By following these steps, you can effectively develop and test a Python script for detecting NSFW images in PDFs using the NSFW API. This automated approach not only saves time but also ensures a higher level of accuracy and consistency in identifying inappropriate content.
Conclusion
In this blog post, we have explored the critical importance of detecting NSFW images in PDFs and demonstrated how to implement an effective solution using Python and the NSFW API. We started by understanding the definition and examples of NSFW content, highlighting the risks and consequences of failing to detect such material. We then delved into the technical challenges of NSFW detection, contrasting manual and automated methods, and underscoring the necessity of accuracy in these processes.
We provided a comprehensive guide to developing a Python script for NSFW detection, covering setting up the NSFW API, parsing command-line arguments, extracting and analyzing images from PDFs, and testing the script. By following these steps, you can automate the detection of inappropriate content, ensuring a safer and more professional environment.
By leveraging the power of AI and the NSFW API, you can significantly improve your content moderation processes, reduce the burden on human reviewers, and ensure that your digital documents remain appropriate and safe for all audiences. We encourage you to implement these techniques in your workflows and stay informed about the latest developments in AI-powered content detection.
For further resources, tutorials, and tools, consider exploring additional documentation and support offered by API4AI and other AI technology providers. With continuous advancements in AI and machine learning, the capabilities of content detection systems will only improve, offering even more robust solutions for maintaining safe digital environments.