MLOps for Computer Vision: Automating the Model Lifecycle
Introduction — Why Autonomous Model Ops Is the Next Competitive Edge
Computer vision is no longer experimental — it's now a core driver of competitive differentiation across industries. From retail shelf analytics and automated quality control to document digitization and brand exposure tracking, enterprises are integrating visual intelligence into their daily operations. However, building a high-performing computer vision model is only half the battle. The real challenge lies in deploying, managing, and continuously improving these models at scale — and doing so without draining engineering bandwidth or overspending on infrastructure.
This is where MLOps for computer vision comes into play. Just as DevOps transformed software delivery, MLOps — short for Machine Learning Operations — is revolutionizing how AI models are developed, deployed, and maintained. For C-level leaders, MLOps represents more than just a technical enhancement. It’s a strategic enabler for accelerating innovation, reducing time-to-value, and mitigating risk.
Traditional model development processes are often siloed, manual, and fragile. A data scientist may train a promising model on a curated dataset, but without an automated pipeline to deploy, monitor, and retrain it in production, the model quickly becomes obsolete. Worse, undetected performance drift can lead to costly errors — from misclassified product images in e-commerce platforms to faulty safety alerts in industrial environments.
Automating the model lifecycle addresses these pain points head-on. It introduces reliability, traceability, and scalability into every stage — from ingesting and labeling raw image data to deploying models to edge or cloud environments, and monitoring real-world performance. By operationalizing vision AI, businesses can ensure that their models continue to deliver accurate, actionable insights — even as data patterns evolve.
Consider this: a global logistics company implementing visual package inspection can reduce returns and operational costs by maintaining consistently accurate detection models. A fintech firm using AI for ID verification can meet KYC compliance faster and more securely by deploying real-time OCR and face-matching models with drift detection in place.
In essence, MLOps is not just about automation — it’s about unlocking sustainable AI-driven growth. For companies investing in computer vision today, the ability to manage models efficiently over time will define tomorrow’s winners. This blog post explores how modern MLOps frameworks can automate the full model lifecycle for computer vision — and how organizations can leverage both ready-made APIs and custom solutions to stay ahead of the curve.
From Proof of Concept to Profit: The CV Production Gap
Many organizations recognize the potential of computer vision and eagerly invest in pilot projects. Yet, a staggering number of these initiatives never reach production. According to industry research, over 70% of AI and machine learning proofs of concept (POCs) fail to move beyond the experimental stage. While the initial demos may be compelling, the journey from a successful prototype to a scalable, revenue-generating solution is fraught with hidden challenges — particularly in computer vision.
The core issue is what experts call the “production gap”. In the context of computer vision, this gap is amplified by the complexity of visual data, high labeling costs, and the volatility of real-world conditions. Models that perform well in a controlled lab environment often break down in the field due to changes in lighting, object orientation, background noise, or unseen edge cases. Without a robust infrastructure to monitor, update, and retrain these models continuously, performance begins to degrade — sometimes without immediate detection.
Moreover, the process of collecting, curating, and labeling visual datasets is still highly manual in many organizations. Data scientists spend an inordinate amount of time preparing data instead of innovating on models. Labeling edge cases or rare object types (like niche household items or obscure product labels) often becomes a bottleneck. This lack of scalability and repeatability introduces delays and increases the cost per iteration.
At the same time, C-level leaders face a dilemma: invest more resources into a custom vision system that may not scale, or delay deployment and risk losing competitive advantage. The pressure to demonstrate quick wins often leads teams to repurpose models in environments where they are not robust, resulting in operational failures and eroded trust in AI.
One way to de-risk this transition is by leveraging pre-trained, production-ready APIs that handle common vision tasks out of the box. For example, using an NSFW Recognition API to filter user-generated content, or a Background Removal API to automate image preparation in e-commerce workflows. These plug-and-play solutions allow organizations to quickly operationalize specific vision tasks without investing in infrastructure or model training from scratch.
Such APIs are not the end goal but a powerful starting point. They enable companies to build early momentum, validate use cases, and gather performance benchmarks. Once these pipelines are in place, teams can gradually expand or replace components with custom-trained models for highly specific scenarios — ideally within a mature MLOps framework.
In the long run, the companies that win in computer vision will be those that can bridge the production gap early, iterate rapidly, and evolve their systems without starting from zero each time. Moving from proof of concept to profit demands not just better models, but better pipelines, automation, and strategic deployment — all of which lie at the heart of modern MLOps.
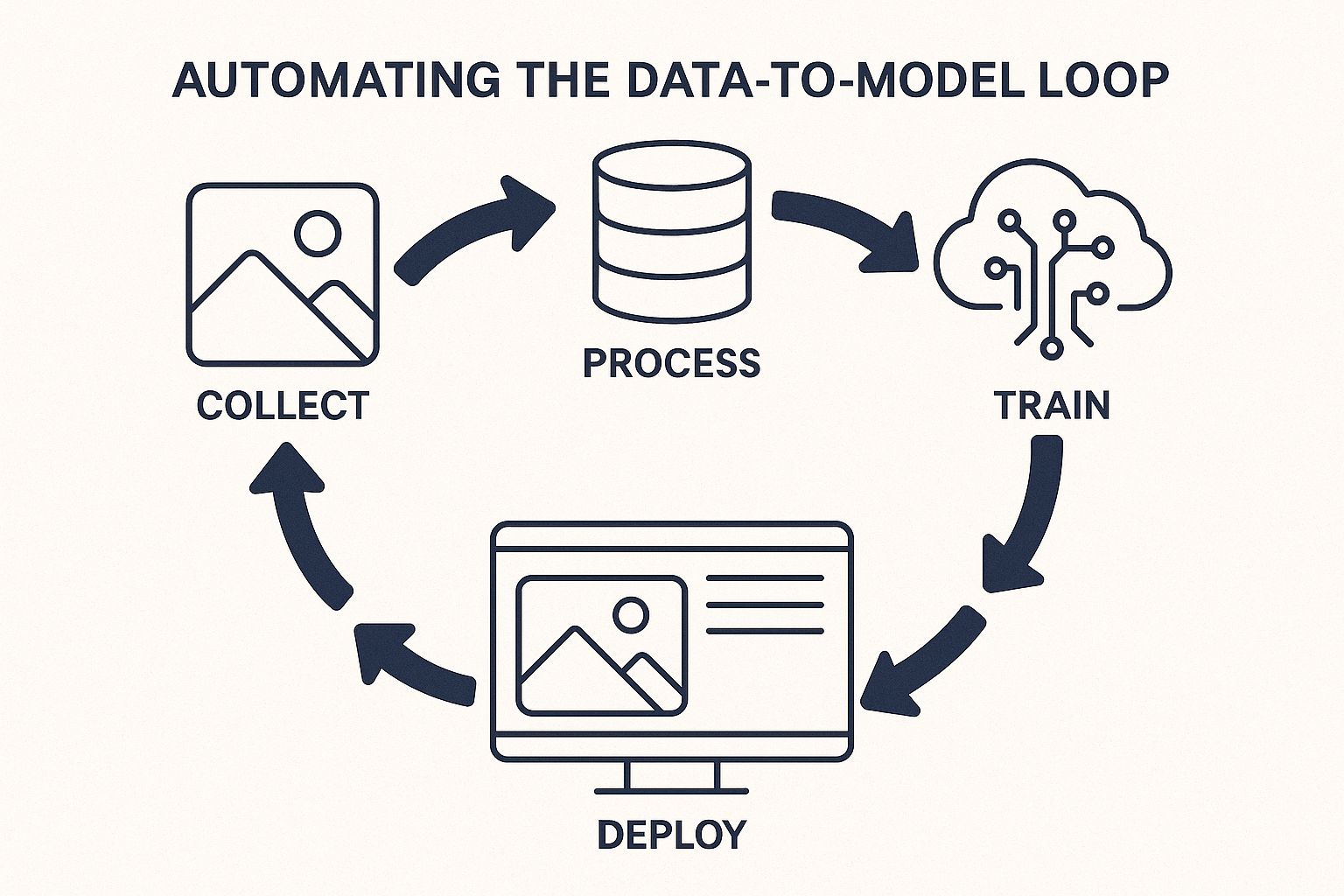
Automating the Data-to-Model Loop
In computer vision, the quality of your model is only as good as the data that powers it. But visual data is uniquely challenging: it’s large, unstructured, and highly variable depending on context. For C-level executives, this means one thing — manual data operations quickly become a scalability and cost bottleneck. Automating the data-to-model loop is the first and most crucial step toward sustainable, enterprise-grade computer vision systems.
The traditional loop — collect, label, train, evaluate — is often slow and resource-intensive. Teams spend weeks sourcing relevant images, manually annotating them, and re-training models every time performance dips or new use cases emerge. As data grows and use cases diversify, this manual approach collapses under its own weight.
Modern MLOps practices bring automation and intelligence into every phase of this loop:
1. Smart Data Ingestion and Cleaning
Instead of pulling in massive amounts of raw data and filtering it manually, automated pipelines now support context-aware ingestion, which prioritizes high-signal images and filters out noise. These pipelines can automatically detect duplicates, remove corrupted or irrelevant files, and tag metadata for downstream tasks. For example, in a logistics use case, images of damaged parcels or misaligned barcodes can be flagged early in the pipeline using object detection logic.
2. Accelerated and Automated Labeling
Manual annotation is one of the most expensive and time-consuming parts of the vision workflow. Fortunately, pre-trained vision APIs — like OCR, Image Labeling, or Furniture & Household Item Recognition — can be used to bootstrap annotation with high precision, reducing the burden on human labelers. These APIs can label large datasets at scale, identify objects, extract text, or even anonymize faces — dramatically cutting down time-to-model.
3. Synthetic Data and Augmentation
When real-world samples are scarce or sensitive — for example, rare product types or regulated content — synthetic data generation and augmentation can fill the gap. By simulating edge cases and introducing variations in lighting, background, and object deformation, teams can expose models to scenarios they might not encounter during early training. This improves model robustness without additional data collection overhead.
4. Versioned Feature Stores and Reproducibility
As data flows become more complex, version control for features and datasets becomes critical. Enterprise-grade MLOps frameworks track which data was used to train which model, when it was updated, and how it performed — ensuring regulatory compliance and auditability. For sectors like insurance, healthcare, or finance, where explainability and traceability are paramount, this kind of transparency is a non-negotiable requirement.
For decision-makers, the takeaway is clear: automation in the data-to-model pipeline unlocks exponential ROI. It reduces cycle times from weeks to days, drives down labeling costs, and lays the groundwork for repeatable experimentation. Most importantly, it positions your organization to respond faster to market shifts and customer expectations, without rebuilding your AI stack from scratch each time.
By integrating ready-to-use APIs where possible and streamlining data operations with MLOps best practices, companies gain the agility to scale their vision initiatives without sacrificing accuracy, compliance, or speed. The result isn’t just a more efficient pipeline — it’s a smarter, more responsive business.

CI/CD for Vision AI — From Training to Real-Time Deployment
Deploying a computer vision model is not the finish line — it’s the starting point of a dynamic, continuous lifecycle. For enterprises to extract real value from vision AI, they must evolve from manual, ad hoc rollouts to automated, continuous integration and continuous deployment (CI/CD) pipelines purpose-built for machine learning. This shift is especially critical for computer vision, where models face constant pressure from real-world variability — changing environments, user behaviors, or product designs.
For C-level executives, the goal is simple: reduce time-to-market, minimize deployment risk, and ensure AI systems stay accurate and reliable in production. CI/CD in the context of vision AI is the operational backbone that makes this possible.
1. Model Registry and Artifact Management
In traditional software, versioning is straightforward. In machine learning, every trained model is a complex artifact — a function of data, code, and configuration. A modern MLOps setup includes a model registry where all trained models are stored with detailed metadata: training data used, model architecture, performance benchmarks, and environment dependencies. This ensures traceability and enables instant rollback to previous versions if new deployments underperform — a critical capability in high-risk applications like biometric authentication or vehicle detection.
2. Seamless Packaging and Deployment
Once a model is trained and validated, it must be deployed across environments — cloud, mobile, browser, or edge devices. This requires robust containerization practices (e.g., Docker) and orchestration (e.g., Kubernetes) that wrap models and dependencies into portable, production-ready units. Whether deploying an Image Anonymization API to a privacy-sensitive healthcare app or a Logo Recognition model into a global ad monitoring platform, the ability to deploy consistently and securely is non-negotiable.
This also includes automated infrastructure provisioning, enabling companies to scale compute resources up or down based on demand — optimizing cost and performance without manual intervention.
3. Staged Releases and A/B Testing
In high-stakes environments, deploying a new model into production without testing is a recipe for disaster. CI/CD pipelines allow for canary deployments (rolling out to a small user group first) or A/B testing (comparing new and current models in parallel). These strategies minimize risk while enabling real-time measurement of business impact, such as increased detection accuracy or reduced false positives.
For example, a retailer piloting a new Object Detection model to automate shelf stock analysis can release it to one store location, monitor its effectiveness, and scale rollout based on verified results.
4. Compliance and Governance by Design
As computer vision becomes more deeply embedded in core operations, ensuring compliance with data protection and industry regulations becomes essential. CI/CD frameworks can embed security scanning, bias detection, and documentation validation into the deployment process. This means every production model is automatically evaluated against compliance checkpoints — a must-have for industries like finance, healthcare, and public safety.
For leadership, the message is clear: CI/CD transforms AI deployment from a bottleneck into a business accelerator.It enables teams to release vision models faster, update them safely, and respond to changing market conditions or customer needs in real time.
More importantly, it reduces operational risk. In a world where AI-driven decisions can impact customer trust, regulatory standing, or safety, the ability to roll out updates — with full observability, version control, and rollback capability — is not just an IT concern. It’s a business imperative.
By integrating vision-specific APIs, such as Car Background Removal or Brand Logo Recognition, into a CI/CD pipeline, organizations can further simplify the delivery of high-impact use cases. These prebuilt components can be deployed and updated as part of a broader machine learning system, helping businesses remain fast, flexible, and future-ready.

Monitoring, Drift Detection & Self-Healing Pipelines
Deploying a high-performing computer vision model is an achievement — but keeping it performant over time is where the real work begins. Visual environments are inherently dynamic. Products change. Lighting varies. Customer behavior shifts. All these changes can silently degrade a model’s accuracy and reliability, a phenomenon known as model drift. Without proper monitoring and maintenance, what was once a valuable AI asset can quickly become a business liability.
For C-level executives, this creates both a risk and an opportunity. The risk is operational — unnoticed drift can lead to costly errors, reputational damage, or non-compliance. The opportunity is strategic — by automating monitoring and retraining, companies can ensure long-term model resilience, reduce downtime, and increase trust in AI systems.
1. Operational Monitoring for AI SLAs
Just like traditional IT systems, AI models in production require real-time monitoring dashboards that track performance against key metrics: inference latency, accuracy, precision/recall, error rates, and cost per inference. These metrics serve as the foundation for AI SLAs (Service Level Agreements), ensuring that deployed models continue to deliver business value.
For instance, a media platform using a NSFW Recognition API to filter user content must continuously track false negatives — any slip could result in harmful content slipping through and damaging brand credibility. Proactive monitoring makes it possible to catch these issues before they escalate.
2. Drift Detection: Catching the Invisible Decay
Drift isn’t always obvious. A model might continue running without throwing errors, but its predictions can become subtly less accurate as real-world data diverges from the training distribution. Drift detection algorithms solve this problem by continuously comparing current input data and outputs to historical baselines.
Computer vision APIs — such as Image Labeling or Object Detection — can be integrated into these monitoring workflows to extract consistent signals and surface early signs of visual distribution shift. For example, if a fashion retailer’s product photography begins to change in style or resolution, these APIs can flag discrepancies that may affect tagging accuracy.
Advanced systems go one step further, analyzing not just inputs and outputs but embedding-level drift — changes in feature space representations that hint at deeper model degradation. These insights are crucial for maintaining high performance in high-volume, customer-facing systems.
3. Automated Retraining and Self-Healing Pipelines
Once drift is detected or performance drops below a predefined threshold, automated retraining workflows can be triggered. These pipelines can pull recent data, use semi-automated labeling tools (e.g., OCR or Logo Recognition APIs), retrain the model, validate it against test data, and redeploy — often with minimal human intervention.
This creates what’s known as a self-healing pipeline — an AI system that maintains itself, learns from new data, and adapts to real-world conditions over time. In logistics, for example, if a package inspection model starts misidentifying new barcode formats, the system can retrain with recent examples and re-deploy the updated model within hours — without disrupting operations.
4. Business Impact of AI Resilience
Ultimately, the ability to detect drift and recover autonomously protects more than just model accuracy — it protects customer experience, brand trust, and regulatory compliance. In industries like finance or healthcare, even minor prediction errors can have serious consequences. For executives, the value of resilient AI is measurable: fewer service disruptions, lower incident response costs, and greater confidence in scaling AI use cases.
Vision AI systems that adapt in real time are not science fiction — they’re a strategic asset made possible by modern MLOps. By combining automated monitoring, drift detection, and retraining, organizations can maintain peak model performance at scale, without growing operational overhead.
Companies that embed these capabilities into their AI stack — whether through custom systems or pre-built services — gain more than technical advantage. They gain the ability to move faster, recover smarter, and deliver consistently better experiences across every customer touchpoint.

Strategic Playbooks — Build, Buy, or Blend?
One of the most important strategic decisions facing companies that invest in computer vision is how to acquire and scale the capabilities needed: Should you build proprietary models and infrastructure from scratch? Should you buy off-the-shelf solutions like cloud APIs? Or should you pursue a hybrid path that combines both?
There is no one-size-fits-all answer. The right approach depends on your business objectives, regulatory environment, internal capabilities, and time-to-value expectations. However, C-level executives need a clear framework to guide this decision — not just from a technical perspective, but from a financial and competitive one.
1. When to Buy: Speed, Simplicity, and Reliability
Cloud-based vision APIs provide immediate functionality without the overhead of data collection, model training, or infrastructure setup. For tasks like background removal, text extraction (OCR), logo recognition, object classification, or face detection, prebuilt APIs offer proven accuracy, high availability, and seamless scalability. This makes them ideal for solving well-defined problems with minimal complexity.
For example, a fashion retailer might use a Background Removal API to prepare product images for online listings — a process that needs to happen in real time, across thousands of images per day. A fintech company might use a Face Recognition API for identity verification in its mobile onboarding flow. In both cases, buying an API means faster integration, predictable costs, and guaranteed performance — all without adding to your internal AI headcount.
This route is particularly attractive when:
Time-to-market is critical.
The use case is standard and doesn’t require specialized training.
Internal AI expertise is limited.
Cost control and simplicity outweigh customization needs.
2. When to Build: Differentiation and Strategic Control
In some cases, the task is too unique, sensitive, or strategically important to rely on external solutions. For instance, if your business relies on detecting very specific visual cues (e.g., manufacturing defects on custom-designed components), or if you’re developing a proprietary dataset that could give you a long-term competitive edge, building your own models becomes a strategic necessity.
Custom-built computer vision systems allow for:
Full control over data, architecture, and performance trade-offs.
Tailoring models to unique visual patterns that prebuilt APIs cannot handle.
Protection of intellectual property and sensitive data.
Integration into specialized workflows or regulatory environments.
That said, building requires significant investment — in data acquisition, annotation, infrastructure, and talent. Without a clear MLOps strategy, many custom projects fall into the trap of endless iteration with little return.
3. The Hybrid Approach: Best of Both Worlds
For most enterprises, the optimal path is not “build or buy” — it’s “build and buy strategically”. This blended model leverages ready-made APIs to accelerate common tasks and prototypes while reserving internal development resources for the most critical, differentiating challenges.
A media monitoring company, for example, might use Logo Recognition and NSFW Detection APIs to handle standard content processing, while building custom models to detect subtle patterns in video streams that are unique to their clients. A logistics firm might start with a generic Object Detection API to identify damaged packages, then evolve into a custom-built model trained on company-specific damage patterns and box designs.
This phased approach allows companies to:
Gain early momentum and prove ROI before committing large budgets.
Reduce risk by avoiding full custom development for every component.
Scale selectively based on long-term strategic needs.
Forward-looking vendors often support this model by offering customization services on top of existing APIs — allowing clients to start fast and evolve toward tailored solutions when the business case is clear. This is where working with a specialized computer vision partner becomes a force multiplier.
For C-level decision-makers, the build-buy-blend choice is not just about software — it’s about long-term agility, cost efficiency, and strategic positioning. The companies that win with computer vision are those that treat it as an evolving capability, not a one-off investment. By combining prebuilt tools where they make sense with custom innovation where it matters most, organizations can future-proof their AI investments and accelerate their path from insight to impact.

Conclusion — Turning Automated MLOps into Sustainable Advantage
Computer vision is no longer a futuristic concept reserved for R&D labs — it is now a core enabler of digital transformation across industries. From e-commerce personalization and industrial automation to real-time compliance monitoring and customer identity verification, vision AI is powering new business models, improving margins, and enhancing user experiences. But to truly capture this value, organizations must move beyond pilot projects and embrace automation at every stage of the AI lifecycle.
This is where MLOps for computer vision becomes a strategic asset. By automating data pipelines, standardizing deployment workflows, implementing real-time monitoring, and enabling self-healing model systems, companies can not only scale their AI efforts but also ensure resilience, compliance, and long-term cost control.
For C-level executives, the key takeaway is this: AI success is no longer defined by building the most complex model, but by how reliably and efficiently that model can operate in the real world. The best-performing organizations are not the ones with the most data scientists, but the ones with the most operationalized AI — systems that are continuously learning, adapting, and improving in alignment with business goals.
Leaders should act now by asking a few critical questions:
Are our current AI initiatives built to scale, or are they stuck in proof-of-concept mode?
Do we have visibility into how our vision models perform in production — and how quickly we can respond to drift or failure?
Are we using prebuilt APIs and automation to accelerate time-to-value where possible?
Do we have a clear roadmap for which parts of our AI infrastructure we should build versus buy?
The answers to these questions will define how ready your organization is to compete in a world increasingly driven by intelligent visual systems.
To accelerate this journey, many enterprises begin by integrating trusted vision APIs — such as OCR, Image Labeling, Object Detection, or Background Removal — into their workflows. These tools provide fast, reliable value and serve as the foundation for more tailored, long-term AI strategies. In parallel, partnering with experienced providers who can support both ready-made solutions and custom development ensures that your investments are not only operationally efficient but also aligned with your unique market positioning.
In conclusion, adopting MLOps in computer vision is not just a technical decision — it is a strategic imperative. Organizations that invest in automating the model lifecycle today will enjoy faster innovation cycles, lower operational risks, and a stronger competitive edge tomorrow. The era of vision AI at scale has arrived — and those with the foresight to operationalize it will lead the way.