OCR + LLMs: From Words to Contextual Insights
Introduction
For decades, organizations have relied on Optical Character Recognition (OCR) to transform scanned pages into digital text. While OCR has been indispensable in eliminating paper silos, its outputs have often remained too raw for true business intelligence. A scanned agreement might yield words, but not clarity on who the contracting parties are, which dates define the terms, or which clauses represent obligations and risks. In a world where decisions are accelerated by data, raw words are no longer enough.
Recent advances in large language models (LLMs) are changing this equation. Instead of producing flat strings of characters, hybrid pipelines that combine OCR with LLMs can now interpret context, structure, and relationships embedded in documents. These systems don’t just read — they understand. They can identify key-value pairs in forms, map clauses to responsibilities in contracts, and highlight critical data points in financial reports. This represents a fundamental leap from digitization to contextualization.
For executives, the implications are strategic rather than technical. When a business gains the ability to automatically extract structured, analytics-ready data from scanned agreements, operational forms, or compliance reports, it unlocks entirely new efficiencies. Risk is reduced because fewer manual interpretations are required. Time to insight shrinks because information is immediately available in context. And the enterprise becomes more agile, capable of integrating document intelligence into governance dashboards, financial systems, or customer-facing processes.
At the same time, confidence and reliability are no longer secondary concerns. Modern hybrid pipelines can assign probability scores to extracted data, giving decision-makers a clearer sense of certainty. This allows leaders not only to act faster but also to trust the information powering those actions.
In short, OCR enriched by LLMs is not merely an IT upgrade — it is a strategic enabler. It allows businesses to move from documents filled with words to datasets filled with actionable insights. In the sections ahead, we will explore how this transformation works, the business impact it delivers, and why forward-thinking leaders are prioritizing these capabilities today.
The Evolution: From Traditional OCR to Intelligent Document Understanding
Optical Character Recognition has been a cornerstone of digital transformation for decades. Traditional OCR systems excel at a specific task: converting images of printed or handwritten text into machine-readable characters. This capability has eliminated manual data entry in countless workflows, from invoice processing to digitizing archives. For a long time, the value proposition was straightforward — speed and accuracy in turning paper into text.
However, for leaders focused on efficiency, compliance, and competitive agility, traditional OCR has shown clear limitations. It produces text, but not meaning. A contract may be digitized, yet the business still needs to manually identify which text corresponds to obligations, renewal dates, or payment terms. A government form may be converted into characters, but without context, it remains a flat document instead of a structured dataset ready for analysis. In other words, OCR historically solved the “what is written” question but left the “what does it mean” challenge unanswered.
This gap is now being bridged by the integration of Large Language Models (LLMs). Unlike classical OCR engines, LLM-enhanced pipelines go beyond character recognition to interpret intent, relationships, and semantic structure. They can detect key-value pairs in forms, classify sections of lengthy agreements, and even highlight anomalies in financial reports. Instead of receiving thousands of words with no hierarchy, decision-makers gain structured data that mirrors how humans naturally understand documents — by grouping, labeling, and prioritizing information.
For executives, the evolution from raw OCR outputs to intelligent document understanding represents more than an incremental improvement. It is a shift in capability that directly impacts strategic operations:
Operational Efficiency: Automated interpretation removes the bottleneck of human review for routine documents.
Risk Reduction: Context-aware extraction reduces misinterpretations, improving compliance and audit readiness.
Scalability: Global operations can process multilingual, multi-format, and even handwritten inputs with a single pipeline.
Time to Insight: Critical business data flows directly into dashboards and analytics platforms without manual structuring.
The leap from OCR to intelligent document understanding parallels the broader trend in enterprise AI: moving from automation of tasks to augmentation of decisions. For industries that depend heavily on agreements, forms, and reports — finance, healthcare, insurance, logistics, and government — this is not just a technical upgrade, but a strategic accelerator.
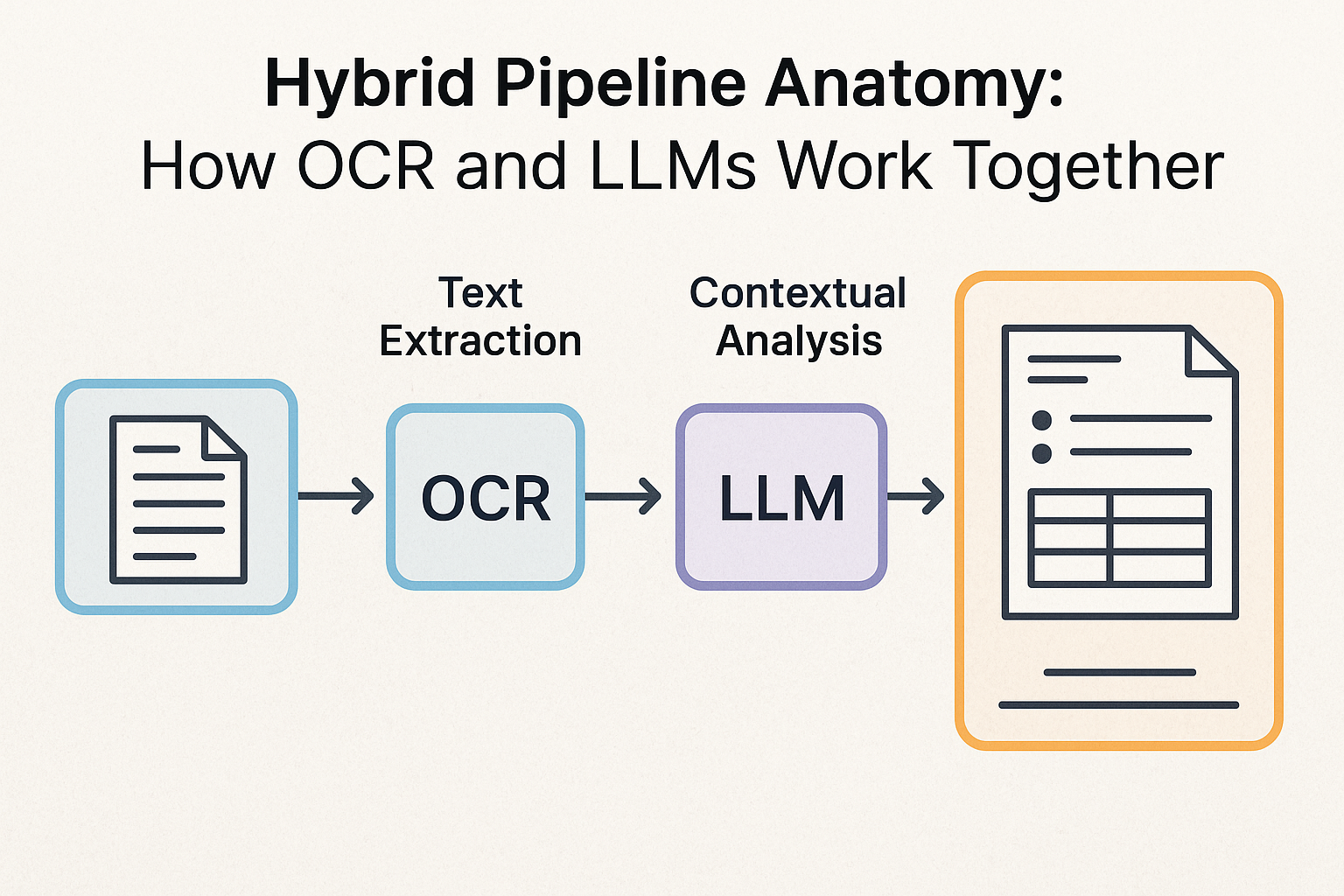
Hybrid Pipeline Anatomy: How OCR and LLMs Work Together
To appreciate the power of combining Optical Character Recognition (OCR) with Large Language Models (LLMs), it is useful to understand how the two technologies complement one another. On their own, each offers value. OCR converts scanned images into text, while LLMs excel at understanding and interpreting language. But when orchestrated together, they form a hybrid pipeline that transforms static documents into dynamic, context-rich data streams that executives can rely on for faster, smarter decisions.
Step 1: OCR as the Foundation
The process begins with OCR, which extracts raw characters from scanned agreements, forms, or reports. Modern OCR solutions can handle diverse input formats — from high-resolution PDFs to mobile photos of receipts — and support multiple languages and even handwritten text. This stage ensures that every visible element on a page becomes machine-readable, laying the foundation for deeper analysis.
Step 2: Structural and Contextual Interpretation via LLMs
Once text is extracted, the LLM takes over. Here, the model analyzes the raw string and organizes it into meaningful structures. Instead of presenting executives with a sea of words, the system identifies key-value pairs, classifies sections, and connects related fields. For example:
In a scanned contract, the LLM highlights parties involved, contract duration, renewal clauses, and financial obligations.
In a government form, it links labels to their corresponding values, such as “Date of Birth” to the extracted date field.
In a financial report, it distinguishes between narrative sections, figures, tables, and appendices, ensuring the data is ready for integration into dashboards or analytics pipelines.
Step 3: Confidence and Reliability Layers
A critical component of the hybrid pipeline is confidence scoring. Instead of treating all extracted data as equal, modern systems apply probability measures to each piece of information. For executives, this means insights are delivered not only with context but also with a clear signal of certainty, enabling risk-aware decisions. For example, if a renewal date is extracted with 99% confidence, it can be trusted for automated workflows; if it falls below a threshold, it can be flagged for human review.
Step 4: Delivery of Analytics-Ready Data
The end result is not just digitized text, but structured, trusted, and analytics-ready data. This makes it straightforward to feed extracted information into ERP systems, CRM platforms, compliance monitoring tools, or custom business dashboards. Instead of data sitting idle in a scanned document repository, it flows into the operational bloodstream of the enterprise.
This hybrid architecture represents a strategic enabler: it doesn’t replace human judgment but ensures that leaders have reliable, structured insights at their fingertips. In practice, it transforms the role of documents — from static records into active contributors to business intelligence.

Business Impact: Analytics-Ready, Trusted Data at Scale
For most organizations, the value of technology is measured not by its novelty but by its ability to improve performance, reduce risk, and create opportunities for growth. This is where the combination of OCR and Large Language Models delivers its strongest impact. By transforming scanned documents into structured, contextualized, and confidence-scored data, enterprises move beyond digitization to true decision enablement.
Turning Documents into Operational Intelligence
In many industries, agreements, forms, and reports represent the backbone of operations. Yet these documents often remain locked in static formats that require manual review. Hybrid OCR+LLM pipelines change this dynamic. Instead of relying on teams of analysts to interpret and re-enter information, organizations receive analytics-ready datasets that flow directly into enterprise systems. This shift reduces time-to-insight from days to minutes, freeing skilled employees to focus on higher-value tasks such as negotiation, compliance strategy, or customer engagement.
Risk Mitigation Through Context and Confidence
Executives understand that bad data is worse than no data at all. A digitized contract with a misidentified renewal date can trigger financial exposure; an incomplete compliance form can invite regulatory penalties. Hybrid pipelines mitigate these risks by layering context and probability onto raw text. When a clause is extracted with 99% certainty, it can safely drive automated workflows. When confidence falls below a threshold, the system escalates the issue for human validation. This not only reduces costly errors but also builds trust in the automation itself.
Scaling Across Borders and Formats
Global enterprises often operate in environments where documents are multilingual, handwritten, or presented in inconsistent layouts. Traditional OCR struggles in such conditions, but modern approaches enriched by LLMs adapt more easily. A French lease agreement, a handwritten medical intake form, and a scanned annual report can all be processed through a single pipeline. This scalability allows organizations to harmonize global operations, reduce fragmentation, and centralize insights without maintaining multiple localized systems.
Driving Strategic Agility
The ultimate impact of analytics-ready data is agility. When executives can access structured information instantly, they make decisions faster, respond to risks sooner, and identify opportunities earlier. Finance leaders can accelerate reporting cycles. Compliance officers can monitor obligations in real time. Operations teams can automate repetitive form handling. This agility translates into competitive advantage: organizations that understand their documents faster than their rivals can negotiate better deals, respond quicker to market shifts, and serve customers with greater efficiency.
In short, the business impact of OCR+LLM pipelines is not about replacing existing processes but elevating them. By embedding intelligence into the very fabric of document workflows, enterprises gain both resilience and speed — qualities that define successful organizations in a rapidly changing economy.

Illustrative Use Cases: Scanned Agreements, Forms, Reports
The true value of combining OCR with Large Language Models emerges when we look at real-world applications. Across industries, executives face recurring challenges tied to the sheer volume and complexity of agreements, forms, and reports. Each represents a potential bottleneck — or, with the right technology, a source of accelerated insight and efficiency.
Agreements: From Contracts to Clear Obligations
Contracts are central to nearly every enterprise, but their complexity often hides critical details. OCR+LLM pipelines can automatically extract contracting parties, key dates, payment schedules, and renewal terms from scanned agreements. Instead of a legal team manually combing through hundreds of pages, executives receive a structured summary that highlights risks, opportunities, and obligations. This enables faster approvals, proactive renewals, and stronger compliance with internal governance and external regulations.
Forms: From Static Fields to Actionable Data
Forms — whether government filings, employee onboarding documents, or customer applications — are often riddled with repetitive fields that traditionally require manual data entry. Hybrid pipelines transform these into structured datasets, capturing key-value pairs like “Name: John Doe” or “Date of Birth: 12/03/1990” with confidence scores attached. This means data flows directly into HR systems, CRMs, or compliance platforms without human retyping, reducing errors and accelerating turnaround times. For executives, this translates into lower operational costs and improved customer or employee experiences.
Reports: From Dense Text to Strategic Insights
Annual reports, audit documents, and performance reviews often contain a mix of narrative sections, figures, and tables. While OCR alone can convert these into text, it does little to preserve structure or meaning. By applying LLMs, organizations can automatically categorize sections, extract financial ratios, flag anomalies, and connect text commentary with numerical evidence. Executives gain not just digitized text, but contextual insights that feed into dashboards and analytics engines, enabling quicker decision-making with higher confidence.
Cross-Industry Applicability
Finance and Banking: Automated loan agreement parsing, accelerated due diligence, faster compliance reporting.
Healthcare: Patient intake forms digitized into EMR systems, insurance claims processed with contextual validation.
Logistics and Supply Chain: Bills of lading and customs forms turned into structured datasets for real-time tracking.
Public Sector: Government applications and records digitized into searchable, auditable databases.
These examples demonstrate how OCR combined with LLMs goes beyond simple digitization to create actionable, analytics-ready assets. For executives, the message is clear: investing in this technology is not just about streamlining document handling — it’s about unlocking strategic insight across every layer of the enterprise.
How Ready-Made APIs Enable Rapid Integration
For many organizations, the prospect of deploying OCR combined with Large Language Models can seem like a major technology project — complex, costly, and resource-intensive. The reality is very different. Thanks to the rise of cloud-based APIs, enterprises no longer need to build entire pipelines from scratch. Instead, they can integrate powerful capabilities into existing workflows quickly and at scale, reducing both risk and time to value.
Starting with OCR APIs as the Foundation
The first step in any hybrid pipeline is reliable text extraction. Ready-to-use OCR APIs provide this capability out of the box, handling diverse document types, languages, and even challenging inputs like low-quality scans or handwritten notes. By embedding an OCR API into existing systems — whether it’s a contract management platform, a CRM, or a compliance portal — organizations establish a foundation of machine-readable text that is both accurate and scalable. This baseline enables the next stage: contextual enrichment with LLMs.
Layering Intelligence with LLMs
Once text has been captured, LLMs can be applied to interpret, classify, and contextualize the output. By orchestrating these technologies, companies gain not just text but structured information: key-value pairs, entity recognition, semantic relationships, and confidence scoring. In practice, this means executives receive dashboards populated with insights rather than documents waiting to be read. Importantly, the modular nature of APIs allows enterprises to add this intelligence layer incrementally, aligning investment with immediate business needs.
Accelerating Deployment While Preserving Flexibility
The advantage of API-based solutions is speed. A pilot can be launched in days, not months, allowing leadership teams to see real results early. As requirements grow, enterprises can extend the pipeline with custom AI development tailored to unique processes or regulatory environments. This creates a balance between quick wins and long-term strategic alignment: ready-made APIs for rapid adoption, and bespoke enhancements for sustainable competitive advantage.
Strategic Investment with Long-Term Returns
While off-the-shelf APIs cover a wide range of needs, some organizations require highly specific solutions — such as parsing niche industry forms, supporting rare languages, or integrating tightly with proprietary systems. Custom development in these cases is not a short-term expense but a long-term investment. When designed thoughtfully, it reduces ongoing operational costs, increases process reliability, and provides a defensible edge over competitors who rely on generic tools.
From Pilot to Enterprise Scale
The combination of cloud APIs and LLMs enables a pragmatic adoption curve: start small, integrate quickly, demonstrate value, and expand strategically. For executives, this means confidence in both near-term ROI and long-term scalability. Rather than a risky, all-or-nothing deployment, enterprises can evolve at their own pace while steadily capturing value from documents that were once static and underutilized.
In essence, ready-made APIs transform the idea of OCR+LLMs from a daunting initiative into a manageable, business-driven strategy. They empower organizations to harness cutting-edge AI capabilities without losing focus on their core mission — delivering growth, resilience, and customer value.

Conclusion
The shift from traditional OCR to hybrid OCR+LLM pipelines marks a turning point in how organizations treat their documents. No longer are scanned agreements, forms, and reports passive records requiring manual interpretation. They are becoming active assets — structured, contextualized, and analytics-ready sources of intelligence that flow directly into decision-making processes.
For executives, the implications are profound. What once demanded teams of analysts, weeks of review, and layers of manual validation can now be achieved in near real time. This reduces cost, accelerates operations, and minimizes compliance risks, while also creating a foundation for more agile business practices. Whether the priority is shortening reporting cycles, enhancing governance, or improving customer experiences, the path forward increasingly depends on how well enterprises can unlock the value hidden in their documents.
Ready-to-use APIs — such as OCR APIs that form the entry point for many hybrid solutions — make adoption practical and low-risk. They enable leaders to pilot quickly, prove value, and then scale confidently. For organizations with complex or highly specific requirements, custom development represents a strategic investment: it not only addresses unique challenges but also establishes long-term competitive advantage by embedding intelligence deeply into workflows.
Ultimately, this transformation is not about technology for its own sake. It is about building resilience, enabling growth, and sustaining advantage in a competitive economy. Leaders who embrace OCR+LLM pipelines today will find themselves with a sharper view of their operations, a stronger grasp of their risks, and a faster route to seizing opportunities tomorrow.
In the digital economy, documents are no longer just words on a page — they are data. And with the right strategy, they can become one of the most powerful drivers of insight and performance across the enterprise.