Synthetic Data for Vision: Scaling Without Manual Labels
Introduction — Why Synthetic Data Is Climbing the Board Agenda
In the race to deploy computer vision solutions that are fast, accurate, and cost-efficient, the biggest bottleneck is no longer model architecture — it’s labeled data. For C-level executives navigating the AI transformation, this challenge is becoming a recurring boardroom topic. Traditional workflows for gathering and annotating real-world images are expensive, time-consuming, and increasingly constrained by data privacy regulations. At the same time, the demand for computer vision in sectors like retail, manufacturing, logistics, healthcare, and digital media is only accelerating.
Synthetic data — artificially generated data that mimics real-world images — offers a compelling way forward. By eliminating the need for manual image collection and labeling, synthetic data can compress development timelines, reduce compliance risks, and open up AI innovation to a broader range of use cases. Gartner predicts that by 2030, the majority of training data for AI models will be synthetically generated. This shift is not just technological — it’s strategic.
From a business perspective, synthetic data enables three key advantages:
Speed to market: Models can be trained on-demand, skipping lengthy real-world data cycles. This agility supports faster iteration and quicker product rollout.
Cost control: Once set up, synthetic pipelines generate massive datasets at a fraction of the cost of human annotation. That means lower OPEX for every AI initiative.
Built-in compliance: Because synthetic images don’t contain personal or copyrighted material, they bypass many of the data governance headaches plaguing real-world datasets.
At the same time, cloud-based computer vision APIs — for tasks like object detection, face anonymization, OCR, and label verification — make it easier than ever to validate synthetic data and integrate it directly into production workflows.
This blog post explores how synthetic data is reshaping the economics of computer vision. We’ll examine the risks of traditional data labeling, the technologies powering synthetic pipelines, and the business cases where it delivers the most ROI. Whether you're scaling an existing vision system or planning a new one, understanding synthetic data is quickly becoming a C-suite imperative.

The Manual-Labeling Bottleneck — Cost, Risk, and Lost Opportunity
For organizations investing in computer vision, the journey often stalls at a deceptively simple step: labeling data. Despite advances in AI algorithms, most supervised vision models still require thousands — if not millions — of labeled images. Traditionally, these labels are generated by teams of human annotators, often through outsourced services or internal labor. What appears to be a tactical task at first glance carries significant strategic costs and operational risks.
Hidden Costs Behind Manual Labeling
Manual annotation is not just expensive — it's unpredictable. The average cost to label a single image ranges from $1 to $3, depending on the complexity of the task. For large-scale projects, this quickly balloons into six- or seven-figure costs, particularly when datasets must be refreshed frequently to adapt to changing conditions (e.g., new products, updated packaging, changing lighting environments).
Moreover, quality control is a persistent issue. Inconsistent labeling across teams, misinterpretations of visual features, and human fatigue all contribute to noise in the data — which, in turn, reduces model accuracy and increases downstream debugging costs. Poor data results in poor AI outcomes, no matter how advanced the model.
Delays That Erode Competitive Advantage
Manual data pipelines slow down innovation cycles. It can take weeks or months to collect, clean, label, and validate real-world datasets — especially when the subject matter is rare, regulated, or seasonal (e.g., industrial defects, medical imagery, snow-covered roads). In fast-moving markets, these delays translate into missed revenue opportunities and slower customer response.
For enterprises competing on AI capabilities — in product recommendations, autonomous systems, visual search, or smart retail — speed is a differentiator. Relying on slow, manual workflows makes it nearly impossible to iterate and deploy models at the pace required to lead the market.
Compliance, Privacy, and IP Risks
Regulatory frameworks like the EU AI Act, GDPR, and emerging data protection laws in the U.S. and Asia have introduced new layers of risk. When using real-world images, companies must ensure that personally identifiable information (PII) — such as faces, license plates, or sensitive scenes — is either removed or managed in compliance with strict legal standards.
Failing to do so can result in heavy fines, reputational damage, and legal exposure. Even anonymization techniques can fall short when datasets are shared across borders or used for model training without proper safeguards. Organizations in highly regulated industries, such as finance or healthcare, face even tighter scrutiny.
Moreover, using publicly sourced images — scraped from the web or social media — can create intellectual property and copyright challenges, limiting commercial use or triggering takedown risks.
Strategic Impact at the Executive Level
At a strategic level, manual labeling diverts capital and talent away from higher-impact areas. C-level leaders must consider:
Opportunity cost of tying up budget in labor-heavy data ops instead of product R&D or go-to-market.
Data governance complexity, which adds layers of legal and IT review cycles.
Inflexibility in responding to new business needs (e.g., launching in new markets or adapting to new compliance frameworks).
The result? Many vision projects stall in the proof-of-concept phase, fail to scale, or underperform in production — not because the model isn’t good enough, but because the data foundation is too fragile.
In the next section, we’ll explore how synthetic data eliminates these roadblocks — not by improving annotation, but by eliminating the need for it entirely through artificial generation of labeled datasets.
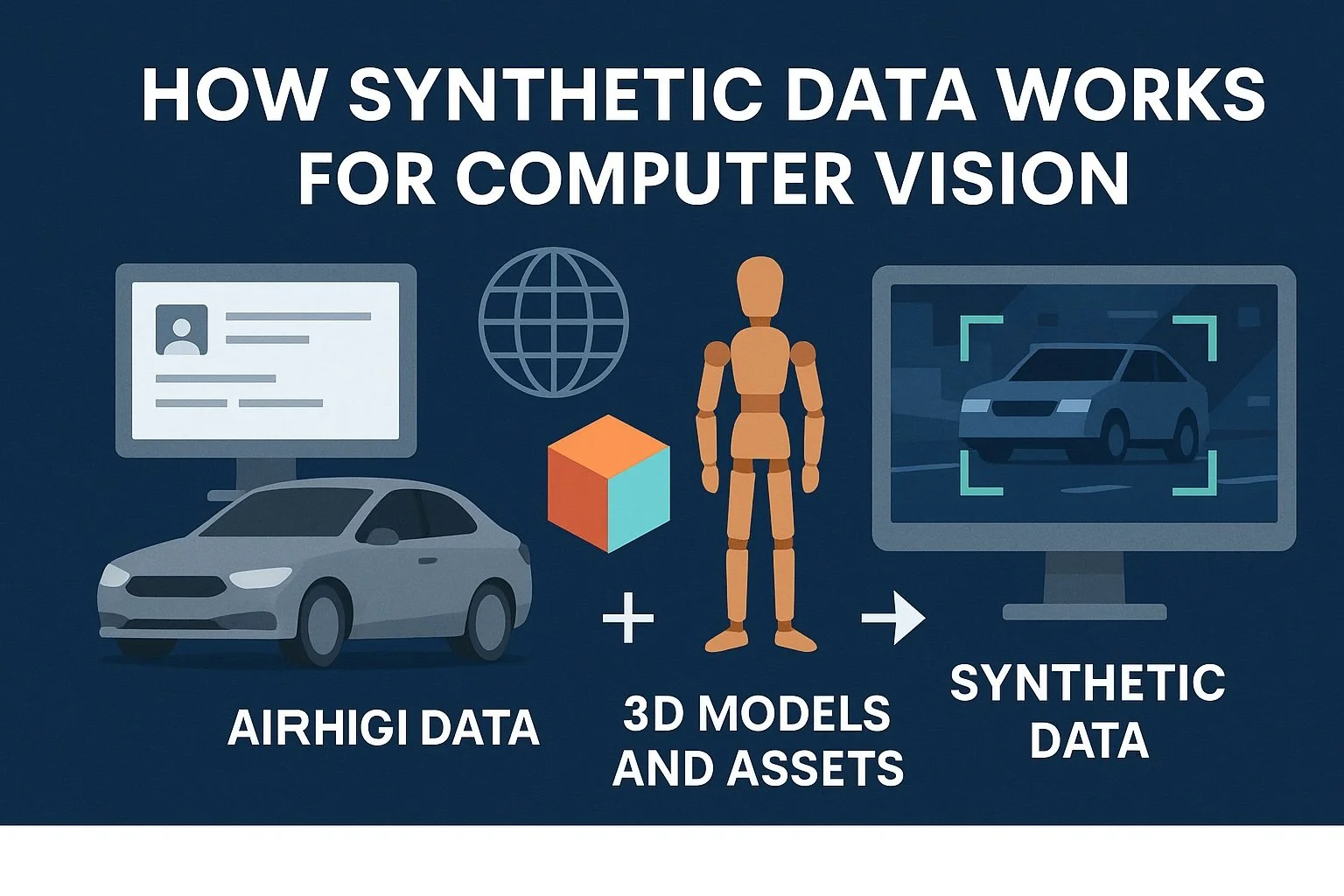
How Synthetic Data Works for Computer Vision
Synthetic data is rapidly emerging as a game-changer for computer vision. Instead of relying on manual collection and labeling of real-world images, synthetic data is algorithmically generated — with labels automatically included. This allows organizations to bypass traditional bottlenecks while gaining precision, scalability, and control.
For C-level executives, understanding how synthetic data works — and how it integrates into the broader AI workflow — is key to making informed investment decisions.
What Is Synthetic Data?
In the context of computer vision, synthetic data refers to computer-generated images and videos that resemble real-world scenarios, complete with accurate annotations. These datasets are not captured by cameras but are produced using a range of advanced technologies such as:
3D rendering engines: Simulate realistic environments, lighting, textures, and object positioning (e.g., factory floors, retail shelves, streetscapes).
Procedural generation: Randomizes scene parameters (e.g., object placement, backgrounds, weather) to cover a wide range of conditions.
Generative AI models: Technologies like GANs (Generative Adversarial Networks) and diffusion models generate hyper-realistic imagery based on training inputs.
Hybrid pipelines: Combine synthetic generation with real-world images to create enriched datasets — especially useful when full realism is critical.
These methods produce high-quality images at scale — and most importantly, each image comes with perfect labels for bounding boxes, masks, keypoints, or class categories. No human annotation required.
Closing the “Reality Gap” with Validation Loops
While synthetic images are highly customizable and accurate, one challenge is ensuring that models trained on synthetic data perform well in real-world deployment — a challenge known as the "reality gap."
To bridge this gap, leading companies use cloud-based computer vision APIs to:
Validate model outputs on real images using APIs for object detection, face recognition, OCR, etc.
Benchmark synthetic data against human-labeled samples to ensure performance consistency.
Enhance realism by including background removal, image blending, or noise simulation using services like:
By combining synthetic generation with real-world API feedback, companies can create feedback loops that optimize datasets over time — improving accuracy and generalizability without manual intervention.
Executive-Level Benefits
From a strategic standpoint, synthetic data offers a range of high-value benefits:
Scalability: Generate 100,000+ labeled images in a matter of hours — ideal for training deep learning models at industrial scale.
Precision: Labels are 100% accurate and consistent, eliminating annotation drift and human error.
Flexibility: Instantly simulate edge cases, rare events, or new product variations without waiting for real-world occurrence.
Security and Compliance: Synthetic data is fully anonymous and copyright-free by design — no risk of PII exposure or IP violations.
Cost Efficiency: After initial setup, cost per labeled image drops dramatically — often below $0.01 per image.
In short, synthetic data turns data creation from a slow, error-prone, manual task into a scalable, automated, and compliant process — one that aligns perfectly with digital transformation agendas and AI-first strategies. In the next section, we’ll explore how to quantify the value synthetic data brings to your organization — in dollars, time, and competitive edge.
The ROI Playbook — Quantifying Value From Pixels
For C-level executives, investing in synthetic data is not just about solving a technical challenge — it’s about unlocking measurable business value. Synthetic data shifts the economics of computer vision, reducing costs, accelerating development cycles, mitigating regulatory risk, and ultimately delivering a stronger return on AI investments.
Let’s break down where and how synthetic data generates ROI.
Dramatic Cost Reduction
Traditionally, labeling image data manually can cost anywhere from $1 to $3 per image, depending on the complexity of annotations and the quality control standards applied. When building computer vision models, it’s common to require hundreds of thousands or even millions of labeled images, pushing the total cost of data preparation into the six-figure range — and that’s before model training even begins.
With synthetic data, once the generation pipeline is set up, the cost per labeled image can drop below a cent. That’s because synthetic images come with perfectly accurate, automatically generated labels — no human labor needed. This drastically lowers the cost structure of vision projects and allows for greater experimentation and iteration without financial penalty.
Speed as a Strategic Advantage
Manual data labeling is notoriously slow. From collecting real-world imagery to annotating and validating it, organizations often spend eight to twelve weeks or more building each dataset. These long cycles introduce delays into product launches and model improvements — a critical disadvantage in competitive industries.
Synthetic data changes that dynamic. Companies can generate complete, labeled datasets in hours or days, not weeks. This means faster prototyping, faster training, and faster deployment. For innovation-driven organizations, this time savings translates directly into competitive advantage and faster response to market opportunities.
Built-In Compliance and Reduced Legal Risk
Data privacy regulations like the GDPR and the EU AI Act are making it harder to use real-world images in AI systems — especially those containing identifiable individuals, brand logos, or sensitive content. Navigating these laws requires legal oversight, documentation, and sometimes the removal or blurring of personally identifiable information, adding both time and complexity to the pipeline.
Synthetic data bypasses these challenges entirely. Because it is generated from scratch — with no connection to real people, locations, or copyrighted material — it’s inherently privacy-compliant. This makes legal review faster, lowers the risk of fines, and enables organizations to develop AI responsibly without running into ethical or legal roadblocks.
Better Coverage, Better Models
Some of the most challenging use cases for computer vision — such as detecting rare defects, identifying objects under poor lighting conditions, or filtering explicit content — require data that is hard or impossible to collect in the real world. Synthetic data fills these gaps by allowing teams to create highly specific scenarios, with full control over the conditions, environments, and edge cases represented.
This leads to more robust models that perform better in real-world conditions. When synthetic data is validated using computer vision APIs (like object detection, NSFW recognition, or automated image labeling), organizations can fine-tune accuracy and detect issues early, before deployment. Fewer false positives, fewer user-facing failures, and less time spent debugging models in production all contribute to real bottom-line value.
Executive Metrics That Matter
Synthetic data directly impacts key executive-level performance indicators. It reduces the per-image cost from dollars to pennies, compresses development timelines from months to days, and eliminates many of the legal risks tied to real-world image use. It also enhances agility, allowing teams to quickly adapt datasets to new requirements — whether it’s launching a product in a new region or complying with evolving regulations.
In short, synthetic data improves cost efficiency, operational speed, regulatory safety, and model performance — all at once.
The ROI case for synthetic data is clear. It not only lowers costs but also boosts the velocity and quality of AI initiatives. In the next section, we’ll explore where synthetic data is already delivering these results in the real world — and which use cases are showing the strongest business impact.
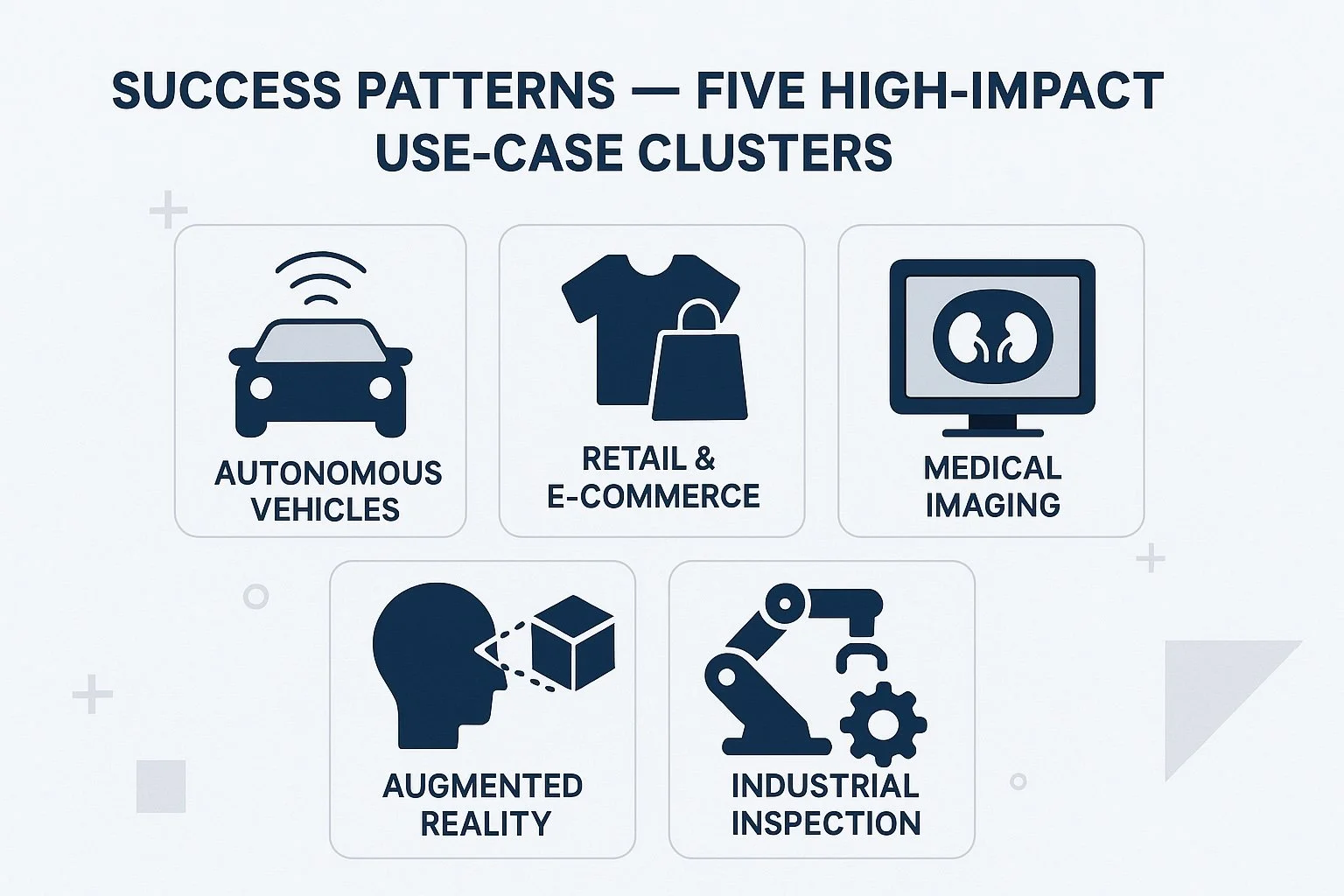
Success Patterns — Five High-Impact Use Cases for Synthetic Vision Data
While synthetic data holds promise across the board, certain sectors and applications are already seeing measurable, strategic gains. These are areas where traditional data collection is either too slow, too expensive, or too risky — and where the ability to simulate large, labeled datasets unlocks rapid development and scalable deployment of computer vision solutions.
Here are five high-impact use case clusters where synthetic data is driving ROI and reshaping industry expectations:
1. Smart Retail and Consumer Goods
In the retail and CPG space, computer vision is used for everything from shelf monitoring to product placement verification and brand visibility tracking. But gathering real-world images for every shelf layout, store format, lighting condition, and packaging variation is nearly impossible at scale.
With synthetic data, retailers and brands can generate photorealistic store scenes — complete with custom lighting, camera angles, and products — to train models that recognize logos, packaging, or promotional displays in real-world environments. This enables more accurate planogram compliance, faster rollout of new packaging, and real-time analysis of in-store conditions.
Relevant technologies: Brand mark and logo recognition, OCR for price tags and signage, background removal to isolate shelf elements.
2. Industrial Inspection and Quality Control
Manufacturers face a major challenge in training vision systems to detect defects in products like electronic boards, rubber clichés, or mechanical components. The problem? Real-world examples of rare or emerging defects are hard to collect and even harder to label consistently.
Synthetic data allows companies to simulate thousands of defect types under various lighting, rotation, and background conditions — long before those defects occur in the real world. This makes inspection systems more proactive, reducing waste, recall risk, and downtime.
Useful tools: Object detection APIs to validate outputs, image labeling APIs for fine-grained segmentation, and custom training pipelines for domain-specific defects.
3. Autonomous Mobility and Smart Infrastructure
Building robust computer vision for self-driving cars, drones, or traffic systems requires extensive training data for diverse conditions — including night scenes, bad weather, low visibility, and rare edge cases like road debris or construction detours.
Synthetic environments can be programmatically generated to simulate these scenarios safely and accurately, covering more edge cases in days than months of real-world driving can provide. For organizations building safety-critical systems, this approach shortens development cycles while improving reliability.
Supporting APIs: Background removal and segmentation for complex environments, custom detection models for infrastructure markers and dynamic objects.
4. Content Moderation and Compliance
For digital platforms, the ability to filter and flag sensitive or explicit content is essential — both for legal compliance and user safety. But relying on real-world examples of such content to train AI models presents obvious ethical and regulatory concerns.
Synthetic data offers a privacy-first, risk-free way to train and fine-tune models for content moderation. It enables platforms to simulate difficult edge cases (e.g., borderline NSFW content or violent imagery) without exposing teams or systems to real sensitive material.
Key technologies: NSFW recognition APIs, face anonymization, and synthetic scenario simulation for moderation testing.
5. Document Intelligence and Automated KYC
Financial institutions, insurers, and legal service providers use vision-based systems to automate the extraction of information from forms, IDs, contracts, and other documents. However, assembling a dataset with enough global diversity (multiple languages, layouts, fonts, distortions) can be slow and error-prone.
Synthetic generation allows companies to create multilingual document datasets with controlled variability — including smudges, folds, glare, or noise — to train OCR models that perform reliably in production.
Powerful API accelerators: OCR APIs for multilingual script recognition, background removal for clean preprocessing, and image anonymization for GDPR compliance.
Why These Use Cases Matter to the C-Suite
Each of these application areas reflects a broader strategic value proposition:
Faster innovation: Synthetic data accelerates time-to-deployment across industries.
Lower cost of experimentation: Teams can test new models or product variations without waiting for data collection cycles.
Stronger compliance posture: Synthetic pipelines reduce reliance on sensitive or regulated real-world imagery.
Scalability: Use cases that were previously limited by data constraints (like rare defects or edge-case moderation) can now scale confidently.
These use cases demonstrate that synthetic data is not just a theoretical tool — it's delivering real business outcomesacross verticals. In the next section, we’ll explore how companies can strategically adopt synthetic data using build, buy, or blended approaches based on their specific needs and resources.

Build, Buy, or Blend — Strategic Paths to Adoption
As synthetic data gains momentum across industries, the question for C-level decision-makers is no longer if to adopt it, but how. There is no one-size-fits-all answer — the right approach depends on your organization’s internal capabilities, compliance requirements, project timelines, and long-term data strategy.
In practice, companies typically follow one of three strategic paths: Build, Buy, or Blend. Each comes with distinct trade-offs in terms of investment, flexibility, and speed to value.
1. Build: Develop In-House Synthetic Data Capabilities
Organizations with advanced internal data science and 3D modeling teams may opt to build their own synthetic data generation pipelines. This involves creating custom environments, object models, simulation engines, and annotation tools — often using 3D graphics libraries or game engines like Unity, Unreal Engine, or Blender.
Advantages:
Full control over data generation and labeling rules
Ability to model proprietary or niche scenarios with high precision
Strong long-term ROI if synthetic data becomes a core capability
Challenges:
High initial setup cost (both talent and infrastructure)
Requires expertise in computer vision, rendering, and automation
Longer time-to-value; best suited for companies with large-scale, recurring data needs
Best fit for: Enterprises with mature AI teams, internal R&D labs, or critical domain-specific data requirements (e.g., aerospace, autonomous vehicles, medical imaging).
2. Buy: Leverage Cloud-Based APIs and Ready-to-Use Tools
For many organizations, especially those seeking fast experimentation or piloting a vision project, purchasing access to synthetic data services and cloud-based APIs is the most efficient option. Vision APIs — such as object detection, face recognition, OCR, or logo recognition — can also be used to validate or refine synthetic datasets before training.
Advantages:
Rapid deployment and scalability
No need to hire specialized 3D or graphics talent
Proven tools with baked-in quality, performance, and support
Pay-as-you-go pricing models align with budget flexibility
Challenges:
Limited customization compared to in-house solutions
Dependency on vendor roadmaps for specific features or formats
Best fit for: Mid-sized businesses, product teams exploring new markets, or enterprise departments looking to validate synthetic data in specific workflows before deeper investment.
Examples of valuable APIs in this category include:
Image Labeling API to test synthetic annotations
Background Removal API to prepare mixed datasets
NSFW Recognition API and Face Anonymization API for compliance workflows
Brand Mark and Logo Recognition API for retail simulation pipelines
3. Blend: Combine Internal Assets with External Acceleration
The blended model is increasingly popular with organizations seeking the best of both worlds. Teams use external APIs and toolkits to handle foundational tasks (e.g., labeling, segmentation, validation), while building bespoke components internally for industry-specific needs — such as unique product geometries, rare defect simulations, or synthetic document templates.
Advantages:
Accelerated time-to-value via proven tools
Customization where it matters most
Flexibility to adapt to changing project scopes
Lower risk and smoother scaling pathway
Challenges:
Requires coordination between internal teams and external providers
Needs clear governance around data ownership and pipeline integration
Best fit for: Enterprises aiming to gradually scale synthetic data capabilities, or organizations looking to experiment now while laying the groundwork for a long-term internal program.
Strategic Decision Points for the Executive Team
When deciding which path to pursue, executive leaders should assess the following:
Time horizon: Do you need to see results in weeks, or are you planning for the next 3–5 years?
In-house expertise: Do you have the technical depth to manage 3D pipelines and simulation engines?
Compliance sensitivity: Do you operate in regulated sectors where control and traceability are paramount?
Innovation velocity: Do you need rapid iteration to test new product lines, regions, or user experiences?
The most successful companies begin with a targeted, high-impact use case, adopt synthetic data through APIs or blended approaches, and scale capabilities based on outcomes. This minimizes risk while maximizing value.
In the final section, we’ll summarize key takeaways and outline a roadmap to help your organization turn synthetic data into a strategic advantage.
Conclusion — Turning Synthetic Pixels Into Competitive Advantage
Synthetic data is no longer a futuristic concept — it’s a present-day enabler of faster, safer, and more cost-effective computer vision systems. For C-level executives, the implications go beyond data science. Synthetic data directly influences business agility, innovation velocity, regulatory compliance, and operational efficiency — all core levers of competitive advantage.
Key Takeaways for Executive Decision-Makers
Labeling is the hidden tax on every vision project. Manual image annotation is slow, costly, error-prone, and increasingly constrained by privacy laws. Synthetic data eliminates this bottleneck by generating perfectly labeled datasets automatically — with significant cost savings and speed advantages.
Synthetic data delivers speed at scale. New datasets can be created in hours, not months, allowing product teams and AI engineers to iterate faster, launch sooner, and respond dynamically to market shifts.
Privacy and compliance are built in. Unlike real-world data, synthetic datasets contain no PII, no copyright risks, and no legal ambiguity. This drastically reduces governance overhead and accelerates regulatory approvals — especially critical for finance, healthcare, legal tech, and any customer-facing platform.
Synthetic data complements — not replaces — real data. Leading organizations use hybrid workflows: generating synthetic data to cover edge cases and rare events, while validating with real-world samples using tools like object detection, image labeling, or anonymization APIs.
Strategic flexibility is key. Whether building internal generation capabilities, buying access to proven vision APIs, or blending both, the optimal adoption path aligns with your organization’s goals, resources, and timeline. What matters is getting started — intelligently and iteratively.
Your First Step Toward Scalable Vision AI
Start by identifying a narrow, high-impact use case — such as detecting product placement in retail, simulating defects in manufacturing, or validating KYC documents. Use synthetic data to build and test a small-scale model. Validate performance with ready-to-use APIs for labeling, segmentation, or content moderation. Track time saved, cost avoided, and accuracy improved.
From there, define your organization’s longer-term data strategy:
What can you automate?
Where do you need customization?
How do you ensure compliance and scalability?
Final Thought
By 2027, analysts expect more than half of all training data for vision models to be synthetic. Companies that invest early — and thoughtfully — will not only cut costs and reduce risk, but also deliver faster AI-driven products and services to market.
Synthetic data is not just a technical solution. It is a strategic lever for digital transformation, and a catalyst for next-generation AI. The organizations that embrace it today will define the benchmarks of tomorrow.